
AI visibility is simple: can systems like ChatGPT, Claude, Gemini, Perplexity, and other answer engines read enough public information to explain your organization correctly?
For many organizations, the first problem is not strategy. It is access. A site can look excellent to a human visitor and still be unreadable to the AI systems people now use to research vendors, advisors, and services.
The robots.txt file that closed the door
In a recent client file, the website was professionally made. It looked good, explained the business, and had real credibility signals. But it had one hidden problem: its robots.txt file blocked the AI crawlers the organization actually wanted to allow.
The file was blocking GPTBot, ClaudeBot, Google-Extended, Applebot-Extended, CCBot, Amazonbot, Bytespider, and other crawlers with the same instruction: Disallow: /. In plain English, that means: do not crawl this site.
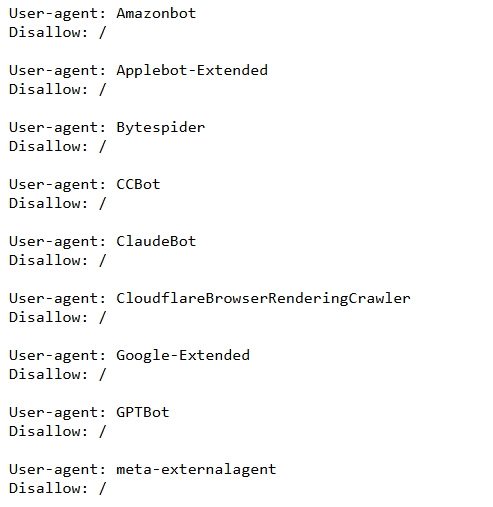
This is why the site was effectively invisible to well-behaved AI crawlers. Humans could visit it. The design could be beautiful. But systems that respect robots.txt were being told to stay out.
Precision matters. robots.txt does not control the whole internet. Bad actors can ignore it. But serious search, indexing, and AI crawlers use it to understand what they may access. If you block the crawlers you need, your best content may never be considered.
How to check your own site
Your robots.txt file usually sits at the root of your website. To check it, type your domain followed by /robots.txt.
For example: https://yourwebsite.com/robots.txt
When that page opens, look for crawler names such as GPTBot, OAI-SearchBot, ClaudeBot, Claude-SearchBot, Google-Extended, Applebot-Extended, CCBot, or similar agents. If you see Disallow: / under one of them, that crawler is being told not to access the site.
Do not change this file blindly. Sometimes blocking a crawler is intentional. The point is to know whether the block matches your business goal. If you want to be found, cited, or summarized by AI systems, blocking the relevant crawlers may work against you.
What AI systems need
AI visibility is not only a crawler issue. Once access is open, the site still needs clear public proof. AI systems look for named services, location signals, explanations, internal links, FAQs, source links, and pages that say plainly what the organization does.
For a site like Nord Paradigm, useful signals include the services page, the AI diagnostic path for Quebec SMEs, the ISO 42001 page, the FAQ, and articles about Law 25, AI governance, Breach, and Breach Pro.
The first audit is simple
Before publishing more content, check the basics:
- Open /robots.txt and confirm which crawlers can read public pages.
- Verify that your sitemap contains the pages you want indexed and cited.
- Make sure your key pages are linked from your main navigation or service pages.
- Use plain language for what you do, who you serve, and where you work.
- Keep French and English pages equally useful if your market is bilingual or francophone.
The right question
The right question is not: "Is AI talking about us?"
The better question is: "If someone asks ChatGPT or Claude about our organization today, can those systems read enough public information to answer correctly?"
If the answer is no, the fix may start with a small file at the root of the website.